1. KNN 개념
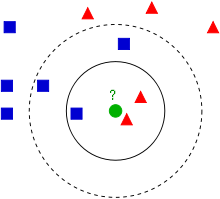
K-최근접 이웃 알고리즘이다. 말 그대로 K개의 가장 가까운 이웃 중에서 가장 공통적인 항목, 과반수에 의해 객체를 분류하는 방식이다. 위 그림을 예로 들어보면, K= 3일 경우 빨간색 2, 파란색 1이기 때문에 초록원은 빨간색을 부여받게 된
다. K=5일 겅우에는 빨간색 2, 파란색 3이므로 파란색을 부여받게 되는 것이다.

이러한 KNN은 머신러닝 중 지도학습에 속하고, 그 중 분류에 속한다. 지도학습인 이유는 정답이 있는 주어진 데이터를 활용해 카테고리에 다라 분류하는 문제이기 때문이다.
2. 장/단점
1) 장점
- 단순하고 효율적임
- 초기 데이터 분포의 가정이 필요 없음
- 별도의 훈련이 필요없음(저장)
- 수치 기반 데이터 분류 작업시 성능이 우수함
2) 단점
- 설명력이 떨어짐
- K 선택이 중요함
3. 주의할 점
변수별 데이터 범위에 따라 영향도가 매우 크게 차이날 수 있기 때문에 거리 기반의 모델의 경우 Scaling이 필수.
4. KNN 구현
import numpy as np
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
iris = load_iris()
knn = KNeighborsClassifier(n_neighbors = 3)
X_train, X_test, Y_train, Y_test = train_test_split(iris['data'], iris['target'], test_size=0.25, stratify = iris['target'])
Y_train
knn.fit(X_train, Y_train)
y_pred = knn.predict(X_test)
print("prediction accuracy: {:.2f}".format(np.mean(y_pred == Y_test)))prediction accuracy: 1.00
'프로젝트(진행중) > 머신러닝 한 걸음씩' 카테고리의 다른 글
| Accuracy(정확도), Recall(재현율), Precision(정밀도), F1 Score 총정리 (0) | 2021.10.05 |
|---|---|
| EP 05. RNN부터 LSTM까지 이해하기 1 (0) | 2021.09.22 |
| EP 03. 나에게 필요한 머신러닝 찾아내는 방법(with 생활코딩) (0) | 2021.08.01 |
| EP 02. 과적합과 정규화 (0) | 2021.07.26 |
| EP 01. 경사하강법 (0) | 2021.07.19 |




댓글