모델을 짰으면 그 모델이 얼마나 잘 작동하는지 확인해야 하고, 그때 여러 지표를 확인한다. 대표적인 4가지 Accuracy(정확도), Recall(재현율), Precision(정밀도), F1 Score의 개념부터 장단점까지 한번 정리해보자!
1. Accuracy(정확도)
내가 예측한 건들 중에서 정답을 맞힌 건수의 비율이다.
수식으로는 이렇다.
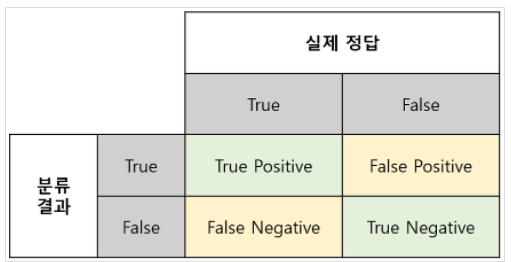

단점 : 정확도의 역설
Negative의 실제 비율이 너무 높아서 희박한 가능성으로 발생할 상황을 제대로 분류하지 못하는 경우가 생길 수 있다. 예를 들어 내일 운석이 떨어질지 여부를 예측한다면 100%가까운 정확도를 아무런 모델 없이 만들 수 있다. Negative만 예측하는 모델을 만들면 Accuracy는 높을 수 밖에 없다.
이럴 경우를 대비해서 필요한 지표가 Recall(재현율)이다.
2. Recall(재현율)
Recall의 개념은 다음과 같이 정의할 수 있다.
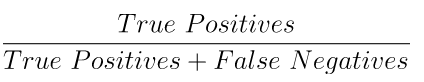
쉽게 설명하면 실제로 True인 데이터를 모델이 True라고 인식한 데이터의 수다. 이 부분에서는 내가 만든 모델이 얼마나 진짜를 잘 찾았는지의 비율로 생각할 수 있다. True가 발생하는 확률이 적을 떄 사용하면 좋다.
단점
하지만 아까의 운석 문제에서 항상 운석이 떨어진다고 예측하는 분류 모델의 경우 recall이 1이 나올 것이다. 운석이 떨어진 날에는 아주 정확하게 맞힐 것이기 때문이다. 때문에 Precision이 필요하다.
3. Precision(정밀도)

내가 만든 모델이 Positivive라고 예측한 것들 중에서 얼마나 정답을 잘 맞추었는지의 비율이다. 수식을 보면 Recall과 상충되는 개념을 가지고 있다. False Positive가 높아지면 False Negative가 낮아질테니 하나가 높아지면 하나는 낮아진다.
4. F1 Score
이 정밀도와 재현율을 적절히 활용하는 지표이다.

정밀도, 재현율 둘 중 하나가 0에 가깝게 낮을때 지표에 잘 반영될 수 있도록 하기 위해 산술평균이 아닌 조화평균을 쓰고 있다. 예를 들어 아까와 같이 recall이 1, precision이 0.01일 때 산술평균 F1 Score는 0.505지만 조화평균은 0.019인 그다지 높지 않게 나온다.
※참고
https://eunsukimme.github.io/ml/2019/10/21/Accuracy-Recall-Precision-F1-score/https://pacientes.github.io/posts/2021/01/ml_precision_recall/
https://hleecaster.com/ml-accuracy-recall-precision-f1/https://thebook.io/080227/ch07/04/08-01/
머신러닝 분류 모델의 성능 평가 지표 Accuracy, Recall, Precision, F1 - 아무튼 워라밸
분류를 수행할 수 있는 기계 학습 알고리즘을 만들고 나면, 그 분류기의 예측력을 검증/평가 해봐야 한다. 본 포스팅에서는 분류 모델의 성능을 평가할 수 있는 지표 Accuracy, Recall, Precision, F1 Score
hleecaster.com
'프로젝트(진행중) > 머신러닝 한 걸음씩' 카테고리의 다른 글
| 실무에서 추천 시스템을 만들어 보며 느낀 것들 (0) | 2022.04.17 |
|---|---|
| 추천 시스템 정리 (0) | 2022.02.21 |
| EP 05. RNN부터 LSTM까지 이해하기 1 (0) | 2021.09.22 |
| EP 04. KNN(최근접 이웃) 개념과 장단점 (0) | 2021.09.06 |
| EP 03. 나에게 필요한 머신러닝 찾아내는 방법(with 생활코딩) (0) | 2021.08.01 |




댓글